Research
The 2012-13 Creative Commons Research agenda
Purpose
- Because minimal data exists on usage of CC tools, those who share content openly are denied knowledge of the impact of their contribution and CC lacks evidence to promote the value of its licenses. We want creators of open content to understand how their actions contribute to the broader commons.
- Creative Commons needs to measure the impact of its licenses to better make the case for the social and economic value of open licensing.
- Successful organizations collect data on activities and use it to iteratively improve performance.
- Facts are needed by Creative Commons (CC) to inform our direction.
- We are excited by new tools that enable CC to measure and highlight impact.
- Questions arising from data analysis will drive the future research agenda.
The research agenda initially responds to two factors - minimal data exists on the impact of CC, and the launch of version 4.0 of the suite of CC licenses represents a significant intervention by CC in the open community. At its core, CC facilitates the legal sharing of digital content. Changes to our licenses may impact how people - across our key communities of Affiliates and users in the GLAM, Education, Public sector, Science and Data fields, as well as Policymakers - license materials and use them. The adoption and use of 4.0 licenses and changes in use of CC licensed materials will reflect the impact of the new version. We need to examine data on license use (applying the license and using licensed materials) to identify that impact. For example: will there be less porting? will adoption amongst key communities increase? will licensing and use of works such as databases and others protected by 'neighboring rights' increase?
We intend to measure our impact
CC intends to initiate an ongoing process for analysis and reporting of metrics to gauge impact. Measuring impact is a challenging research goal and we aim to put in place an ongoing analytical framework before 4.0 is launched (estimate launch date is December 2012). This first six-month phase (commenced in July 2012) will set a baseline and foundation for data driven analysis. Qualitative analysis may commence in January 2013 and will be directed by questions arising from data results. Initially data will be captured to answer the following questions that reflect CC impact (via the 4.0 intervention):
1. What is the number and growth rate of CC licensed materials worldwide?
2. What is the use of CC licensed materials worldwide?
3. We aspire to answer: what is the reuse of CC licensed materials worldwide?
4. We aspire to identify: what is the ratio of 'best practice' attribution and 'best practice' reuse of CC licensed materials to total CC licensed materials?
5. What is the ecosystem in which CC operates?
6. We aspire to answer: in the absence of CC what would the open ecosystem look like?
7. What is the broader public perception of CC? and
8. What is the impact of CC activities?
To achieve this before December 2012 is an aggressive but vital ambition, and is a rare opportunity to show how the work of CC (4.0 is core to all CC operations) affects the commons.
Other important performance metrics to be captured within the CC organization include:
9. Large scale/high profile adopters of CC licenses;
10. Translations of CC license deeds;
11. Indications of a strengthening CC Affiliate network; and
12. Diversification in the funding base of CC.
Concurrent with the above metrics is an ongoing case study of CC impact. It seeks to highlight the performance of CC intervention in the open education field, specifically by answering:
13. How does the active CC-led intervention for U.S. Dept. of Labor (US DOL) Trade Adjustment Assistance Community College Career Training (TAACCCT) grantees achieve the goals of the US DOL TAACCCT program?
Data derived from these thirteen focal points will be made publicly available (CC BY licensed). CC metrics may ultimately be available directly in real time. This is a first step towards that goal.
Five projects address the thirteen research questions
- CC Licensed material metrics
- CC Ecosystem
- Public perception of CC
- Impact of CC activities
- Open Educational Resources (OER) case study
Details of each project are below. If you have any feedback, can help and/or contribute please contact Anna at creativecommons dot org .
1. CC Licensed material metrics
The objectives for the version 4.0 suite of CC licences include:
- Support existing adoption models and frameworks;
- Interoperability;
- Internationalization;
- Recognize and address impediments to adoption amongst key communities (data, public sector information, education, science, GLAM etc.);
- Long lasting.
The Research questions we seek to answer that will measure the impact of CC licenses are:
- What’s the number and growth rate of CC licensed materials worldwide?
- What’s the use of CC licensed materials worldwide?
- We aspire to answer: What’s the volume of re-use/remixing of CC licensed materials worldwide?
- We aspire to identify how well the terms of CC-licenses are complied with. Of all of the re-use/remixing we identify, how much comes with proper attribution, for example?
These questions are asked by our friends in the open community, funders, and CC needs greater visibility to where, how and which CC licenses are being used. Reuse is critical to measure as an indicator of quality and collaboration. Because licenses are central to CC and the open community, this data may reflect the value of investment in CC and guide future CC initiatives. Ultimately we may show how CC licenses and activities have facilitated growth in the value of the global commons.
We intend to initiate a systematic process of gathering and analyzing data, with the aim of capturing metrics before, during, and after the 4.0 launch. We will target emerging areas of public sector information, data and education, and will highlight large and/or significant adopters of CC licenses. This preliminary phase is dependent upon data availability.
The data described below is needed to answer the research questions. It is segmented into 2 data collections: world (total overall) and specific sites (as case studies with more detailed data).
http://wiki.creativecommons.org/images/a/a7/Screen_Shot_2012-08-15_at_12.12.06_PM.png
{kind=link}
World data
The ‘world’ data represents a top level number that best represents the total number of CC licensed materials worldwide and their use. Previously we obtained this data via search engines and we aim to use an improved approach, as outlined below:
| We seek to answer | by indicating: | using data: |
|---|---|---|
| What’s the number and growth rate of CC licensed materials worldwide? | Marking - applying a CC license to content | Daily time series of total CC marked works by Jurisdiction, License type, License version, Domain (Site) |
| What’s the use of CC licensed materials worldwide? | Use | Daily time series of total use of CC marked works by Jurisdiction, License type, License version, Domain (Site) |
| We aspire to answer: What’s the re-use of CC licensed materials worldwide? | Re-use, Remix | Daily time series of total remix of CC marked works by Jurisdiction, License type, License version, Domain (Site) |
| We aspire to explore how well the terms of CC-licenses are complied with. Of reuse we identify, how much comes with proper attribution? | Best practice attribution | To be explored |
A possible source for this data may be the CC server/s, and CC may develop a tool by which users of CC licenses may track use and reuse of materials to which they have applied CC licenses. The tool may indicate use and attribution practices.
Key Sites
We have nominated sites that contain CC licensed materials for deeper analysis.
| We seek to answer | by indicating: | using data: |
|---|---|---|
| What’s the number and growth rate of CC licensed materials on the site? | Marking - applying a CC license to content | Time series of CC marked works by Jurisdiction, License type, License version, Domain (site) |
| What’s the use of CC licensed materials on the site? | Use | Time series of use of CC marked works by Jurisdiction, License type, License version, Domain (site) |
| We aspire to answer: What’s the re-use of CC licensed materials on the site? | Re-use, Remix | Time series of remix of CC marked works by Jurisdiction, License type, License version, Domain (site) |
| We aspire to explore how well the terms of CC licenses are complied with. Of re-use we identify, how much comes with proper attribution? | Best practice attribution | To be explored |
| How many people are impacted by CC licenses? | Number of users of CC licensed content | Number of users of largest sites holding CC content - as an indicator |
Data is being obtained via specific sites and personal contacts at those sites (where it is not publicly available). CC staff have enthusiastically nominated over fifty large repositories with CC content but due to limited resources we will refine it to a maximum of twenty. As an indication they currently include:
If you would like to suggest another major site or source of CC licensed materials please contact Anna at creativecommons dot org directly. Key sites for deeper analysis will be selected on the basis that they contain predominantly CC licensed materials, are large, obtaining license data is relatively straightforward and new/ anticipated fast growth sites. Where data is available it will be obtained to the highest granularity (article, page, blogpost, image, video, song) possible. We are able to provide a deeper level of data from key sites, for example, CCMixter data clearly indicates remixing, PLOS articles are all CC BY and their site provides rich data on article use, and from MOOCs (Massive Online Open Course) we can show trends in the number of people using CC licensed content. In the future we hope to work closely with key sites to analyze their data. Data may be aggregated by medium (e.g. total number of CC licensed photos across Flickr, Wikimedia Commons, Internet Archive etc.). Ultimately we aspire to establish a real time data feed but during this first phase we are collecting data in a variety of ways.
A site-by-site approach creates several data issues: different items of measurement; different data collation methods (personal contacts, websites, scripts etc); poor visibility to metrics methods of many sites etc. This is discussed in more detail in notes below. There will be data gaps in this data collection as the data availability is dependent upon each site. It is expected that the ‘world’ data will include site specific data - it can be used as a cross check at this stage.
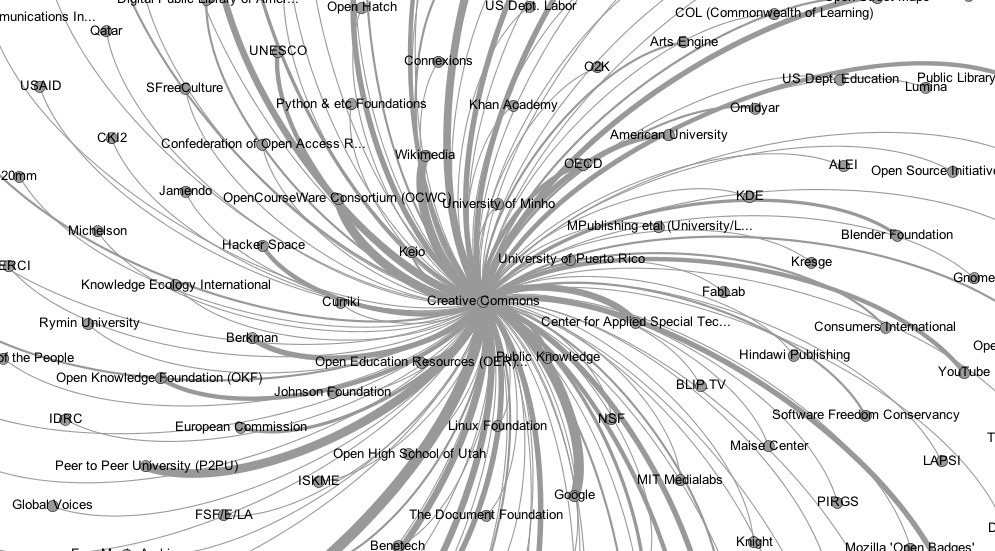
2. The CC Ecosystem
Potential funders often ask questions similar to “how would the Open ecosystem look if CC didn’t exist? How would the ecosystem be affected without CC?” Secondly explicitness about the CC network may assist decisions and policy making by changing the framing of how people think about CC, indicating the intangible value of CC by pinpointing our visibility worldwide, and as a demonstration of our openness and transparency. Ultimately we may show how CC licenses and activities have facilitated growth in the value of the global commons.
What is the CC ecosystem?
Initially we define the ecosystem as the network in which CC operates. Creative Commons often must respond to events over which we have little control or influence. These events arise from the fields of technology, society and non-users of CC licenses, and economic, regulatory and environmental influences. CC exerts some control and influence over licensing of digital content; users of CC licenses, our Affiliates and the digital commons, and the technical infrastructure we use. CC has a high degree of control over our internal processes, how we communicate and promote our work and our suppliers.
Phase 1
Understanding the current state of our ecosystem. We firstly need to identify the CC ecosystem and create a base for conversations about CC. This will provide a tool for answering key questions about intangible value.
To do this CC staff brainstormed a list of entities they are proud to name as contacts and informally allocated them to groups. We nominated the groups as: Legal, Education, GLAM, Technology, Science, Policy, Business, Funders, and International. From this we will create a publicly available, mapped dynamic network that reflects the global spread and depth of CC networks. Specifically, we will map key entities that CC works with regularly and/or considers an important friend. A first draft shall be completed for internal feedback in September 2012.
Phase 2
A public draft for comment is aimed for release in December 2012. It may be initially used to create ongoing conversations aimed at answering:
- Who is affected by CC interventions?
- What is the place and importance of CC within the ecosystem?
- In the absence of CC in the ecosystem, what would the ecosystem look like?
- How do we work with other entities in the space to achieve mutual goals?
- Is this space growing?
- Where are the gaps and weaknesses in the CC ecosystem?
- Is there a role for CC to address any gaps and weaknesses?
The map will develop iteratively, for instance more detailed public information may be added to our contacts, indicators of network depth, and more!
Dovetailing the two major projects described above are two smaller important projects and a large ongoing case study of CC impact.
3. What is the public perception of CC?
Phase 1: We intend to create a system for ongoing monitoring public perception of CC, as indicated by mentions in Twitter, Blogger and Wordpress. Phase 2: Longitudinal analysis of trends in public perception may reflect development of Creative Commons and its role within the global commons. Significant findings may lead to deeper qualitative analysis. Ultimately public perception influences the intangible value of the CC brand.
4. What is the impact of CC activities?
Phase 1: A frequent outcome of CC activities is that interest is generated and that drives people to look at the CC website. We intend to initiate a systematic process of regular analysis of website metrics (initially via Google Analytics) - to highlight indications of increased awareness of CC, outcomes from campaigns, and long term growth in the CC profile. This may ultimately merge with the license metrics project. Initially we can show hits to license deeds for H1+2 of 2012 (Source: Google Analytics and Fusion Tables). We will also note major milestones such as: major adopters; translations of CC license deeds; the strength of our affiliate network and others.
Phase 2: Significant findings may lead to deeper qualitative analysis. Ultimately we may show how growth in the value of the global commons has been enabled by our activities.
5. OER Case study
We intend to describe the performance of CC intervention in the open education field (a sector of high opportunity), specifically by answering: How does the active CC-led intervention for DOL TAACCCT grantees achieve the goals of the US DOL TAACCCT program? The DOL TAACCCT program is a high profile, large scale project reflecting use of CC licenses by U.S. TAACCCT Community College Grantees. Materials created via TAACCCT funding must be CC BY licensed. Potential impact indicators we are watching for include: increased access to education worldwide; cost savings; reduced teacher/faculty preparation time; enhanced quality; accelerated learning; innovations through collaboration. Research relating to this project is available at http://open4us.org/resources/#Research . Ultimately this OER case study may show how CC licenses and activities have facilitated growth in the value of the global open education movement.
Notes, disclaimers and caveats
Definitions of non-technically correct terms used:
- Marking - applying a CC license (or CC0 public domain mark) to content. This is a once off event that occurs usually when the item is made available.
- Use - the viewing/reading/listening/linking to a CC licensed item.
- Re-use/Remix - actively taking parts of the CC licensed item/s and merging (mixing) them into other items to create a new item (e.g. video and music remixes, remixed open textbooks or mixed open courseware).
- Site - domain/platform e.g. Flickr, Wikipedia, YouTube, CC Mixter, Vimeo, Bandcamp, Soundcloud, Wordpress, Blogger, Public Library of Science, Directory of Open Journals, Khan Academy, Science Commons, Government sites.
- Type - CC BY; CC BY-SA; CC BY-ND; CC BY-NC; CC BY-NC-SA; CC BY-NC-ND. Also includes CC0.
- Version - version 1.0 (Dec 2002), version 2.0 (May 2004), version 2.5 (June 2005), version 3.0 (Feb 2007).
Consistency is a major challenge with this data. This work uses materials from a wide variety of sources that use different collation techniques and so may not be consistent. This includes data across different time periods - where data is unavailable estimates have been made. A decision was made to obtain the highest possible granularity in each item of measurement, but each item differs, for example one photo does not equal one educational course or one journal article as an item of measurement. Every effort has been made to standardize the data for consistency, however inaccuracies may result, especially in this early draft phase. To address this sources have been made available wherever practical for the reader to investigate calculation methods within each source. Data used may also have been cleaned.
Data will been obtained ethically from publicly available sources (websites) or inhouse (Google Analytics), however some data has been supplied using personal contacts within key sites - we have little influence in how it is calculated by others and are very grateful to these sources for going beyond their remit to supply us with any data. In many instances we have no visibility to detailed breakdowns of the data (by license type, jurisdiction) but data is made available by us to the fullest extent of availability. This is why details of license type/jurisdiction is available for some sites but not all - it is dependent upon data availability and reliability.
Time series data is essential to highlight patterns of use, and the data to be used is specific enough to be measured over the long term. Any time series data is influenced by the different dates of introduction of Creative Commons licenses into jurisdictions, and versions (4.0 anticipated Dec 12). An intention was to build upon prior work undertaken by Creative Commons concerning license statistics, however that work was heavily caveated with reliability concerns (e.g. volatility in the estimation algorithm, differences between Google and Yahoo results relating to license types, although positively correlated by jurisdiction and volume) and the method used can no longer be replicated, so we advise that the two time series be kept separate, although both are estimates only. We believe using CC servers will result in more accurate statistics. Secondly, we advise that the ‘global’ data and site data be kept separately and not summed. This is because there may be double counting between the two sources.
This study is not exhaustive nor does it reflect the totality of Creative Commons licensed materials and where estimations have been required they have been conservative. As such these representations may be considered conservative, low baselines.
All care has been taken to compile this data but Creative Commons accepts no responsibility for the ways in which it may be used by others. This is a first draft and we are still in the initial phase of this project so inaccuracies and corrections are expected.
http://wiki.creativecommons.org/images/4/4a/Screen_Shot_2012-05-21_at_3.44.17_PM.png
{kind=link}
Discussion
Please email Anna at creativecommons dot org and/or join the commons-research mailing list.
Previous entries:
Open Research
CC and related tools and movements for open research:
- http://creativecommons.org/science
- http://learn.creativecommons.org
- http://en.wikipedia.org/wiki/Open_Access
Research about CC and the commons generally
Resources
- Participatory Media Lab at Singapore Management University run by Giorgos Cheliotis
- Debate page listing articles and critiques concerning CC.
- Metrics - Creative Commons metrics portal for getting data about CC, processing it and viewing it
- ODEPO - A SMW-based database of online educational projects.
- OER Resources - A SMW-based database of resources about OER.
- http://theinfo.org/ - Studying large datasets, with a particular emphasis on access to these datasets
- Add more!