DiscoverEd Sprint (June, 2010)
Contents
Overview
- What: A sprint on development of DiscoverEd; see DiscoverEd Specifications for possible areas of work
- When: Tuesday, June 15 through Thursday, June 17, 2010
- Where: Wills House, Michigan State University, East Lansing, MI (map)
Attendees
- Asheesh Laroia (OpenHatch / Creative Commons)
- Raphael Krut-Landau (OpenHatch / Creative Commons)
- Nathan Yergler (Creative Commons)
- Alex Kozak (Creative Commons)
- Ali Asad Lotia (open.michigan)
- Kevin Coffman (open.michigan)
- Todd Shunneson (MSU Global)
- Prabode Weebadde (MSU Global)
- Brendan Guenther (MSU vuDAT)
- Timothy Barney (MSU vuDAT)
Travel & Accommodations
- Directions to Wills House
- Brendan Guenther will provide MSU Guest Parking Passes when you arrive in the morning
- Area Hotels (mention MSU for discounted rate)
Agenda
This is a draft, subject to change.
Tuesday
- 9:00 AM - Welcome
- DiscoverEd Context: Why, When, Where are we going? (10 min)
- Introductions
Developers introduce themselves, give brief statement on what they've done with DiscoverEd, what they're interested in working on. (5 min ea.) - MSU Context: AgShare, FSKN, etc (Chris Geith, 10-15 min)
- 10:30 AM - Identify Themes, Possible Blocks of Work
- 11:30 AM - Pair up and begin work
- 4:45 PM - Brief report back from each group: unexpected issues, things to bring to the group as a whole, etc.
Wednesday
No schedule; work as pairs.
Thursday
- 3:30 PM - Pairs begin to make sure work is pushed to Gitorious, determine next steps
- 4:00 PM - Full report back: pairs report on progress and state of their code. Pairs are encouraged to identify follow up steps they will take post sprint to see tasks to completion.
Preparation
In order to minimize time spent configuring laptops, etc, please try to do the following before arriving at the sprint:
- Make sure you have prerequisite software installed and working:
- git (Windows users, see http://progit.org/book/ch1-4.html and http://code.google.com/p/msysgit/)
- Java 1.6 JDK
- Eclipse (not required, but can make life easier)
- Generate an SSH public key (if needed; see http://progit.org/book/ch4-3.html for some instructions)
- Create a Gitorious account and add your SSH key to it
Outcomes
- Daily report blog posts: Day 1, Day 2, Day 3
- Areas of Work:
- Plugins for retrieving metadata from additional sources.
Currently DiscoverEd discovered metadata from feeds, OAI-PMH, and RDFa. This allows people running instances of DiscoverEd to supplement that through a plugin that retrieves metadata from databases, web services, etc, and indexes it with the resource. This work was completed during the sprint.
- Mapping metadata fields to simple, "human" query syntax.
DiscoverEd uses RDF to model metadata, meaning fields have identifiers that look like web addresses. Work was begun to allow site operators to specify short, human readable labels for these identifiers. This will allow DiscoverEd sites to easily expose arbitrary metadata fields to users for searching, without writing additional code.
- Enabling users to add or correct metadata about results.
Communities may wish to allow their users to supplement or correct metadata about results. Work was begun on enabling this through the DiscoverEd metadata store.
- Improved RDFa and provenance support.
Building on work previously begun by Asheesh Laroia and Raphael Krut-Landau at Creative Commons, we integrated an improved RDFa parser in the source tree, and merged support for provenance in the metadata store. This lays the foundation for limiting DiscoverEd searches to metadata provided by specific curators.
- Plugins for retrieving metadata from additional sources.
- Summary email
- Whiteboard Photo
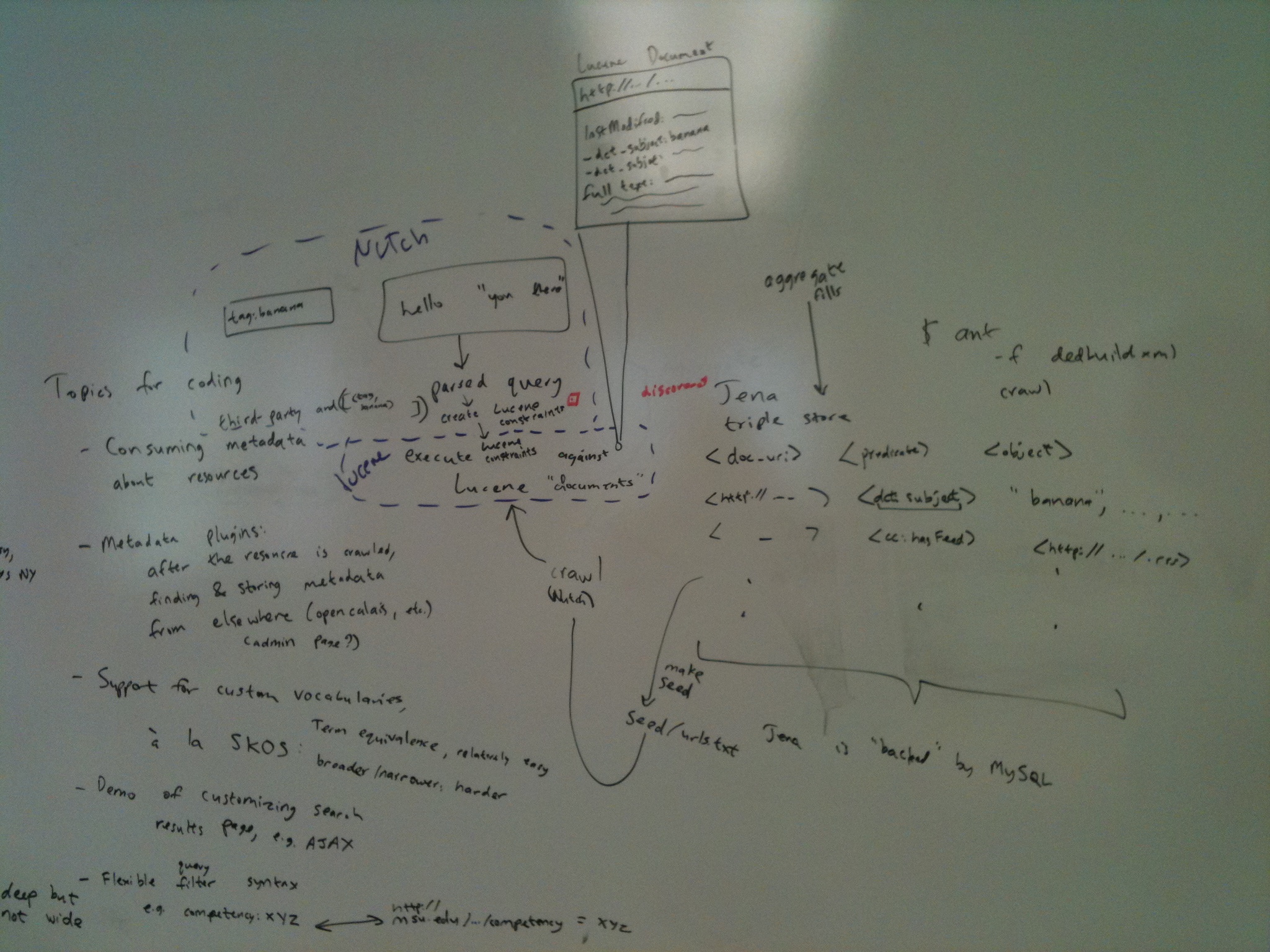{kind=link}
- Next steps